David Jolly Muganzi, Catherine Misango Namara, Timothy Mwanje Kintu, Linda Atulinda, Raymond Bernard Kihumuro, Bonaventure Ahaisibwe, Victor M. Montori
Sylvia K. Ofori, Emmanuelle A. Dankwa, Emmanuel Ngwakongnwi, Alemayehu Amberbir, Abebe Bekele, Megan B. Murray, Yonatan H. Grad, Caroline O. Buckee, Bethany L. Hedt-Gauthier
Julian T. Hertz, Kristen Stark, Francis M. Sakita, Jerome J. Mlangi, Godfrey L. Kweka, Sainikitha Prattipati, Frida Shayo, Vivian Kaboigora, Julius Mtui, Manji N. Isack, Esther M. Kindishe, Dotto J. Ngelengi, Alexander T. Limkakeng, Jr, Nathan M. Thielman, Gerald S. Bloomfield, Janet P. Bettger, Tumsifu G. Tarimo
Davis E. Amani, Harrieth P. Ndumwa, Jackline E. Ngowi, Belinda J. Njiro, Castory Munishi, Erick A. Mboya, Doreen Mloka, Amani I. Kikula, Emmanuel Balandya, Paschal Ruggajo, Anna T. Kessy, Emilia Kitambala, James T. Kengia, James Kiologwe, Omary Ubuguyu, Bakari Salum, Appolinary Kamuhabwa, Kaushik Ramaiya, Bruno F. Sunguya, Ntuli Kapologwe




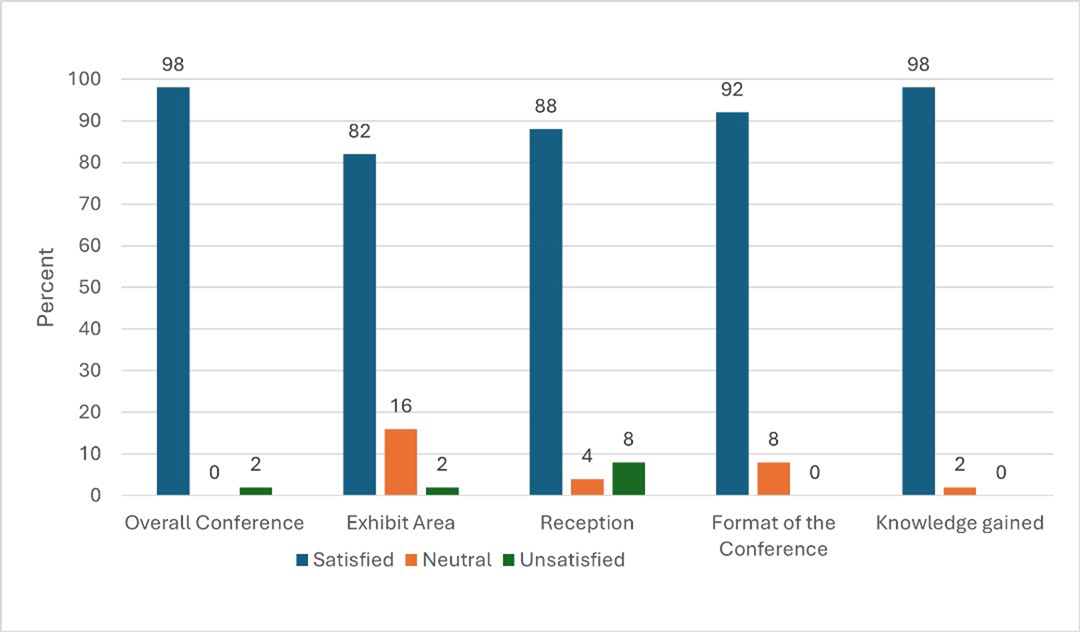{kind=link}
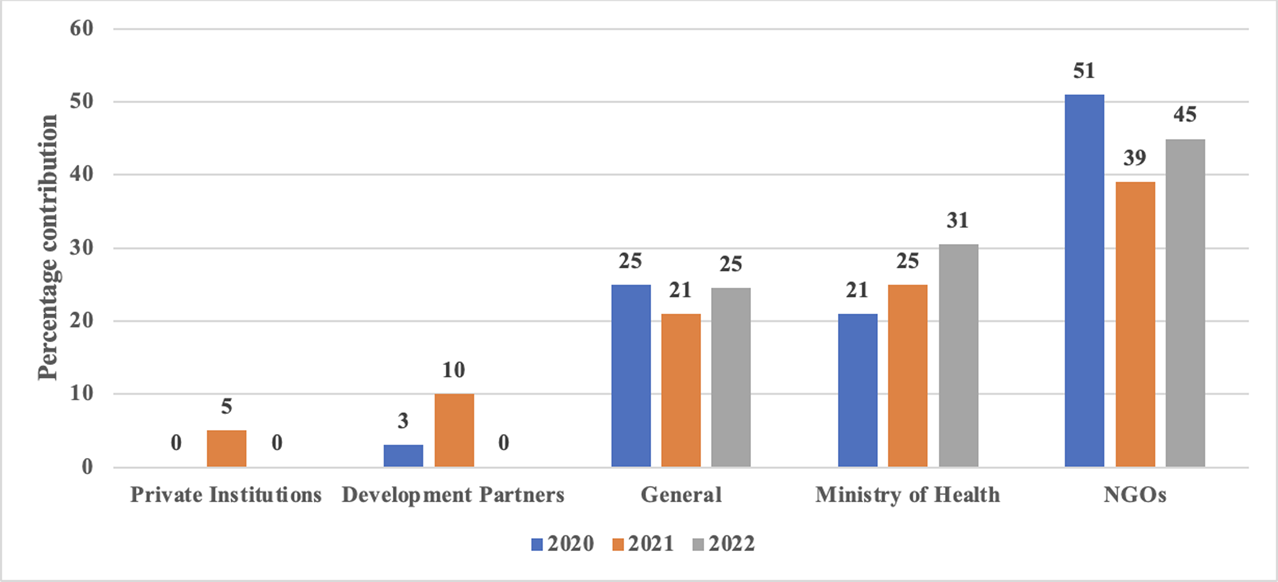{kind=link}
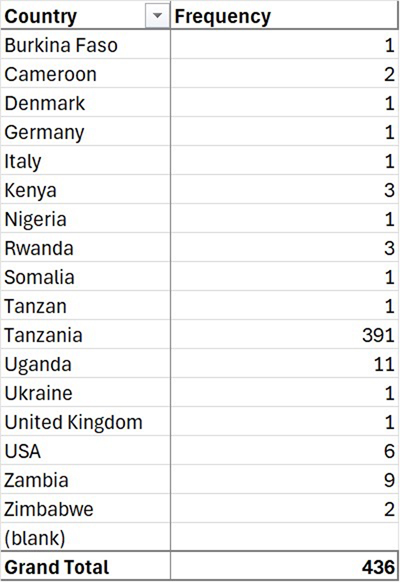{kind=link}